基于深度学习知识追踪研究进展(综述)数据集模型方法
本文共 3440 字,大约阅读时间需要 11 分钟。
基于深度学习的知识追踪研究进展
计算机研究与发展 中文核心期刊
看看之前写的课程综述,在看看别人的工作,距离还是很远啊,拆解拆解他们工作做的不错
基于深度学习的知识追踪(deep learning based knowledge tracing,DLKT)
本文常用符号定义
| 符号 | 定义 |
| 知识成分KC | |
| 题目 | |
DLKT 领域开创性模型DKT
DKT以循环神经网络(recurrent neuralnetwork,RNN)为基础结构.RNN 是一种具有记忆性
的序列模型,序列结构使其符合学习中的近因效应并保留了学习轨迹信息[17].这种特性使RNN(包括长短期记忆网络[18](long short term memory,LSTM)和门控循环网络[19](gated recurrent unit,GRU)等变体)成为了DLKT 领域使用最广泛的模型.DKT 以学生的学习交互记录为输入,通过one-hot 编码或压缩感知[20](compress sensing),
被转化为向量输入模型.在DKT 中,RNN 的隐藏状态
被解释为学生的知识状态,
被进一步通过一个Sigmoid 激活的线性层得到预测结果
.
的长度等于题目数量,其每个元素代表学生正确回答对应问题的预测概率.具体的计算过程如下所示:
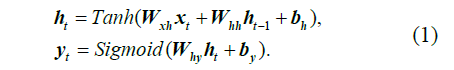

相对于以BKT 为代表的传统机器学习模型,DKT 不需要人工标注的数据就有更好的表现(AUC
提高了20%[21]),且能够捕捉并利用更深层次的学生知识表征[22-23],这使其非常适合以学习为中心的教学评估系统2 DKT 的改进方法
可解释性差、长期依赖问题和学习特征少是DKT模型最显著的3 个问题,许多研究许多研究者致力于对其进行扩展和改进,以解决这些问题.我们将各种改进方法梳理为下图

下表总结了各种模型所属的改进方向类别和其主要的改进方式


表 2 DLKT 领域公开数据集简述、下载链接及使用其的模型
| 数据集 | 简述 | 下载链接 |
| Synthetic | DKT 模型使用的模拟数据集,它模拟了 2000 名虚拟学生,他们回答了来自 5 个虚拟知识点的 50 个问题.仅在此数据集中,所有学生回答问题的顺序相同 | https://github.com/chrispiech/ DeepKnowledgeTracing/tree/ master/data/synthetic |
| Static2011 | 来自一个大学级的工程静力学课程,具有 333 个学生在 1223 个问题上的 189927 个交互 | https://pslcdatashop.web.cmu.edu /DatasetInfo?datasetId=507 |
| KDDCup2010 | 2010 年 KDD 杯比赛开发数据集,具有 574 个学生 在 436 个问题上的 607026 个交互 | https://pslcdatashop.web.cmu.edu /KDDCup/downloads.jsp |
| EdNet | 由 Santa (一个人工智能导学系统)收集的大规模 分层的学生活动数据集,包含 784309 名学生131317236 个交互信息,是迄今为止发布的最大的 公共交互教育系统数据集 | https://github.com/riiid/ednet |
| Junyi | 来自 Junyi Academy (一个在线教育网站),除 EdNet 外数据量最多的开源数据集 | https://pslcdatashop.web.cmu.edu/ DatasetInfo?datase tId=1198 |
| ASSIST2009 | 来自 ASSISTMENTS 在线辅导系统,去掉重复记 录之后,包含4151 个学生在 110 个问题上的 325673 个交互 | https://sites.google.com/site/ assistmentsdata/home/assistment-2009-2010data/skill-builder-data-2009-2010 |
| ASSIST2012 | 包含 27066 个学生在 45716 个问题上的 2541201 个交互 | https://sites.google.com/site/assistmentsdata/ home/2012-13-school-data-with-affect |
| ASSIST2015 | 包含 19840 个学生在 100 个问题上的 683801 个交互 | https://sites.google.com/site/assistmentsdata/ home/2015-assistments-skill-builderdata |
| ASSIST2017 | 包含 686 个学生在 102 个问题上的 942816 个交互 | https://sites.google.com/view/assistments datamining/dataset?authuser=0 |
表4 总结了使用公开数据集的DLKT 模型的性能表现(以大多数论文都采用了的
AUC 指标为基准),表中的数据皆来自于模型初始论文,取最大值.需要指出的是,深度学习模型受参数设置影响较大,且同一个模型在不同论文中的表现也存在较大

未来展望
1)现有DLKT 模型大多使用二元变量来表示题目的回答情况,这种建模方式不适合分数值分布连续的主观题.Wang 等人[86]和Swamy 等人[89]在处理学生的编程数据时,使用了学习者回答的连续快照作为回答情况的指示器,这提供了一种对主观题目建模的方式.而其他的对主观题目的建模方法仍有很大的研究前景. 2)目前DLKT 主要应用于在线教育平台,如何利用好在线平台所提供的大量学习轨迹信息,是研究的难点之一.Mongkhonvanit 等人[95]提供了一种对教学视频观看行为建模的方法,Huan 等人[96]则利用了鼠标轨迹信息.而其他学习特征信息的提取、建模亟需更多的研究.与此同时,特征的添加也是一大难点.对于以RNN 为基础的DLKT 模型来说,输入向量的长度会显著影响模型的训练速度.这就需要使用降维方法减小向量的长度,或者采用其他的嵌入方式(如LSTMCQ)融合更多特征而不增加向量长度.总而言之,学习特征信息的提取、建模、添加将会是DLKT实际应用中的重点研究方向. 3)DLKT 的优秀性能使利用其验证经典教育理论成为可能.如Lalwani 等人[90]验证改进的布鲁姆分 类与遗忘曲线.同时,已提出的教育理论也可以为建模提供指导,如Gan 等人[80]结合了学习与遗忘理论.经典教育理论在DLKT 领域的应用值得更多的研究者加以关注. 4)利用DLKT 模型构建知识图谱.DLKT 模型可以用来发现知识点之间的相互关系,构建出知识点关系图,这可以看作是简化的知识图谱.知识图谱作为当前人工智能时代最为主要的知识表现形式,如何扩展模型的知识结构发现能力,将知识点关系图扩展为知识图谱将会是未来的重点研究方向. 5)目前的DLKT 模型中仍存在许多不确定因素,现有的理论推断并不足以解释DLKT 模型的训练过程.在基于Transformer 的模型中,掩码机制被用来屏蔽后面时间的权重,这是为了防止未答的题目影响已答的题目.而Xu 等人[97]使用双向LSTM 以融合过去和未来的上下文序列信息.两者所依据的原理是相悖的,但都获得了性能提升.如何深入研究,以完整解释DLKT 模型的训练过程,将会是未来的重点研究方向. 6)目前DLKT 主要使用RNN 模型,许多研究已经证明了RNN 的优越性.同时,Transformer 模型,GNN 模型也在知识追踪领域有着优秀的表现.而其他更多模型的应用仍亟需深度研究,对其他深度学习模型的应用将会是重要研究方向. 7)Transformer 相对于RNN 的一大优势就是没有长期依赖问题,但目前基于Transformer 的DLKT 模型却并没有利用好这个优势,如SAKT 和SAINT,它们都将序列长度设置为100,这个长度并没有超过LSTM 的序列学习容量(200).同时,实验显示,位置编码的有无对最终的结果影响并不大.这似乎说明长期依赖与序列关系对KT 任务的影响没有目前所认为的那么大,以此类推,各种学习特征对于KT 任务的影响值得进一步研究.其他的内容可以看文章本身。写的很不错,向其学习
转载地址:http://iihdi.baihongyu.com/
你可能感兴趣的文章
Oracle 物化视图
查看>>
PHP那点小事--三元运算符
查看>>
解决国内NPM安装依赖速度慢问题
查看>>
Brackets安装及常用插件安装
查看>>
Centos 7(Linux)环境下安装PHP(编译添加)相应动态扩展模块so(以openssl.so为例)
查看>>
fastcgi_param 详解
查看>>
Nginx配置文件(nginx.conf)配置详解
查看>>
标记一下
查看>>
IP报文格式学习笔记
查看>>
autohotkey快捷键显示隐藏文件和文件扩展名
查看>>
Linux中的进程
查看>>
学习python(1)——环境与常识
查看>>
学习设计模式(3)——单例模式和类的成员函数中的静态变量的作用域
查看>>
自然计算时间复杂度杂谈
查看>>
当前主要目标和工作
查看>>
使用 Springboot 对 Kettle 进行调度开发
查看>>
一文看清HBase的使用场景
查看>>
解析zookeeper的工作流程
查看>>
搞定Java面试中的数据结构问题
查看>>
慢慢欣赏linux make uImage流程
查看>>